Latitude 5285 半长测
换机缘起
九月底,借来大概一年的 2014 款 ThinkPad S1 yoga 在频繁的使用过程中终于不堪重用,本来进过水的屏幕彻底好不了了。没办法,总不能让我背着重六斤还没算上电源适配器的大家伙每天上下班挤地铁吧我会死的。于是,九月中旬就开始在淘宝上寻找替代用品,因为 Yoga 算是一台 2 in 1 设备,所以还是打算买一台轻便的类似设备,先是盯上了 2017 年发售的 XPS 12 2 in 1,但是因为这系列都是超低压 CPU,性能上我是无法接受的,于是继续翻,运气还不错,DELL 在 Latitude 系列中也推出了类似的 2 in 1 设备,分为使用常规低压 CPU 和常规分辨率屏幕的 5285/5290 系列和使用超低压 CPU 和高分辨率屏幕的 7285/7290 系列。我也不知道 DELL 是脑子抽风了还是一心想学习巨硬和水果的作死精神,总之 Latitude 5285 正好符合我的需求,国内某宝上面也有几家在卖官翻货,价格也是我正好能承受的范围内(学费垫着),于是在国庆前夕,在一趟回学校的公交车上我点击购买了。
 一句充满魔力的咒语
一句充满魔力的咒语
购机波折
顺丰速度还是快,两天到了。我提前下了班回去准备摸新机器。没有做仔细的检查,就看了看外表没有受损屏幕没毛病之后就插盘开始装系统,结果在那个蓝偏紫的首屏,我发现了触摸屏有异样,光标停留在靠近左下角的一个点上,当时还没在意,安装完系统开始用的时候发现真不对,屏幕下部有大范围触摸失灵的情况,马上联系了卖家说明情况,卖家也没多废话就给我说寄回来给我换。
国庆节第一天下午,换的机器到了,这次接手后做了详细的检查,这次发现左下角屏幕不正常,有一小块应该是漏液了。跟卖家反映了情况之后还是愿意给我换一台,但是实在是懒得折腾加上其他配件都到了,也就用了下来。
正文
讲了两大段废话,终于开始正文了,首先先夸一夸这机器。
良心
预留天线
相比起北美良心想,DELL 着实良心不少。比如连 ThinkPad X1 这种机型,你只要是不选配 WWAN 模组,那么你到手的机器里面是不会给你预留 WWAN 的天线的。而 DELL 就不一样了,无论哪个配置都是给你预留好了天线,你想要自己加,买张卡装上去就可以了。但比较遗憾的是,5285/5290 这个型号,不购买带有指纹的机型是不会给你来个留指纹位的后盖的,也就是说除非你愿意在后盖上打个孔,不然是无法使用主板上预留的指纹等设备的接口的。
BIOS
为什么这里要提一句 BIOS 呢?因为我是北美良心想垃圾 BIOS 的长期受害者,原先的国行版 S1 Yoga 使用的单 2.4 GHz 的网卡,而且在 BIOS 里面指定了能够使用的网卡硬件 ID,使得用户无法自行更换更好的网卡。又因为 R6250 的坑爹 2.4GHz 问题,我没有办法让 S1 Yoga 和我的其他设备共存于同一网段下,要么是委曲求全使用性能更差的外部路由当主网关。而 DELL 就不同了,不仅仅不锁设备,BIOS 设定还非常详细实用,除了自带的诊断之外甚至连锁不锁 BIOS 的升降级都给你提供了开关。
手册
DELL 的 Owner’s Manual 是我见过的最详细的笔记本手册,手册中事无巨细的提供了包括但不限于机型参数、拆机方法、拆卸安装配件的方法等等等等。跟着这份手册来,你完全没有看网上拆机教程的必要。
好
LTE & GPS
我现在要吹爆所有预留 M.2 2240 的机器,因为加一个 WWAN 模组加上电信的 20GB 限速卡真的太方便了。Windows 10 对于 WWAN 设备的支持度也相当不错,提供了众多限制后台跑数据的开关,就是传统桌面程序不支持就是了。当时买卡的时候正值 iPhone XS (Max) 发售,Intel 基带背锅的时间段,所以心一狠加了一点钱买了高通的卡(Intel 的卡支持到 Cat.4,而高通的是 Cat.6),实测出来电信 LTE 的速度相当可以,昨天甚至跑出了 4.2 MiB/s 的平均速度。因为这卡还自带 GPS 功能,所以使用系统自带的地图是可以看到实时位置的,照理说其他应用也可以直接使用它提供的 GPS 数据,但最近还没空研究这个,等下次上飞机前看看。
电磁屏
其实原来的 S1 Yoga 国外版本是自带电磁屏的,但是北美良心想在国行版本上以更贵的价格发售了不带电磁屏的版本。我是一直都想买个带电磁屏的设备来记笔记的,结果到了大四出去实习了才拥有这么一台。DELL 采用的电磁压感技术来自于熟悉的 Wacom,笔并没有随机附送,还好也不算是太贵,将近 300 大洋一支还是比水果家的强不少的。但是还是要吐槽一下巨硬,宣布 OneNote 免费之后,连 Office 365 中默认都不带上桌面版的 OneNote 了,默认启用的是 UWP 版本的 OneNote。不过因为之前用的少也不太清楚这两者有什么区别,总之压感至少是没有问题的。
散热
当初机子还没到手的时候寻找了一些国内用户的评测来看,不知为何这模具的散热相当了得,虽然是主动散热但是平常你完全感觉不到风扇的声音。而温度,比如现在我正在使用电池码字,性能设置是开到 100% 的,但是 CPU 频率不高,温度也就只有接近 40℃ ;到手时也做过温度压力测试,甚至可以将 7300U 维持满整个 28 秒不泄,以这个体积的散热系统来说已经是合格的了,更为惊喜的是,BIOS 设定相当给力,长时间烤机也还是可以维持到默频 2.6GHz 之上。而看到中文论坛有说统一模具但是换用八代低压 U 的 5290 甚至可以压住四核八线程的低压 i7。所以我对于这一块是相当满意的。
扩展
机器的扩展是一个 USB 3.1 Gen 1 Type A 以及两个支持 DisplayPort 输出的 USB-C 口,虽然 USB-C 口不支持 Thunderbolt™ 3,但是两个之多的数量比起只带一个 USB Type A 的 Surface Pro 来已经完全是秒杀了。另外 DELL 在推进 USB PD 上也算是比较积极的,在 BIOS 中将供电方式设置为 ExpressCharge 之后就可以开启快充,实测在用 Apple 87W 适配器时充电真的快了很多,而自带的适配器是 45W 的。
携带
携带真的非常方便,键盘一盖就跟平板毫无区别直接拿走。值得一提是这个键盘(保护盖),它 有 键 程。据某位不愿意透露姓名的沙包说,只要是有键程的键盘就比采用新键盘的 MBP 的强,实际体验了一下,果真如此,MBP 上的新键盘甚至不如 Macbook 12 上面的那块同样几乎没有键程的键盘。并且触摸板面积也不算太小,就是手感上确实比不上 S1 Yoga 那个“带弹簧”的触摸板。
因为自带自适应的支架,有桌子的时候竖着放上面一按支架就弹出来了,就是支架的最小角度稍微大了一些,在床上用的时候不是太舒服。
不太行
屏幕
夸了电磁屏,但是对于这块屏幕还是有不满意的地方。不知道 DELL 是为了节约成本或是其他什么原因,分辨率虽然完全合格,1920 x 1280 在 12 寸屏幕上看起来已经是相当精细了。但是在色彩方面,可能就不能说准了,跟几年前的 U2312HM 比起来,色彩甚至出现了一些过饱和,而且面板应该是少了一层过滤,屏幕在镜头前存在彩虹纹,反射光源时同样可见。
续航
虽然自带的电池容量还是有 44Wh 之多,但是不知道是因为挂在 LTE 网络上同时开启了 GPS 的缘故还是 Windows 10 本身的耗电量比较大的问题,一般典型外带最长只有五六个小时电量就降到 30% 左右了(后台开着 KanColle)。也就算是基本够用的水平吧,不过至少不是超低压 CPU,这个水平已经很满意了,只是希望电池能在大点,把缺失的指纹模块那部分的空间利用起来就好了。
抱怨两句
这台机器买的我是非常的舒服,该有的都有,还带了一些惊喜给我,估计之后长久都会带着它跑来跑去了。但是提到跑来跑去就有话要说了,把本来打算写《杂》的话搬到这里来讲吧。
九月头上开始实习之后,深刻体会到了你国上班一族的现状,早起挤地铁挤公交,睡眠不足靠咖啡因撑,中午午休睡成一片,晚上疯狂加班。每天都是固定的日子,也难怪会把人的意志给消磨干净,难得的周末补两天觉打打游戏就没了,自然的也就没什么心思想别的东西了。
所以如果有还没上大学或者是刚开始大学生涯的同学,记得真的要在大学谈次恋爱,不然毕业之后真的没有时间去认真谈恋爱了。
>>>endl;
 2015 年 Roadmap
2015 年 Roadmap 老黄举着新的 Quadro RTX 显卡
老黄举着新的 Quadro RTX 显卡 实时光线追踪样图
实时光线追踪样图 Pascal VS Turing
Pascal VS Turing Turing 架构图
Turing 架构图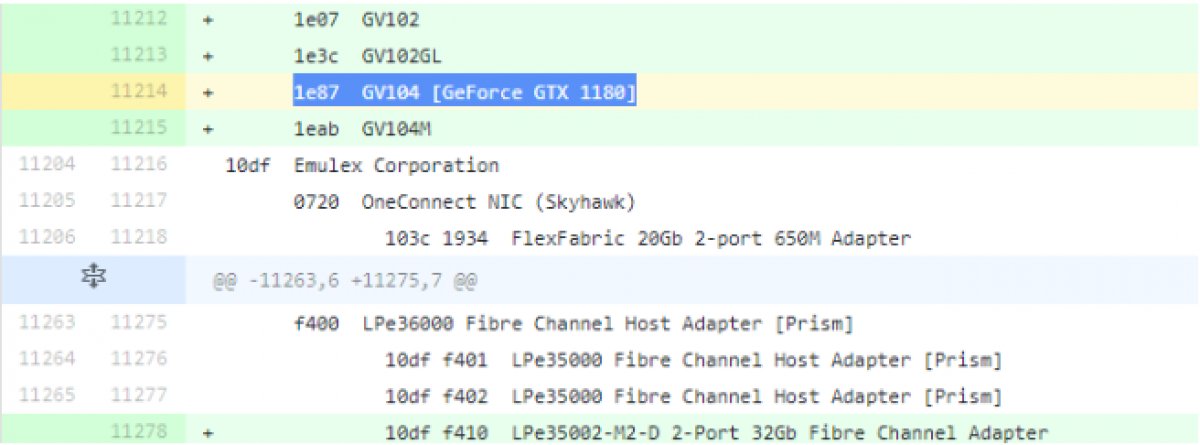 GeForce GTX 1180
GeForce GTX 1180