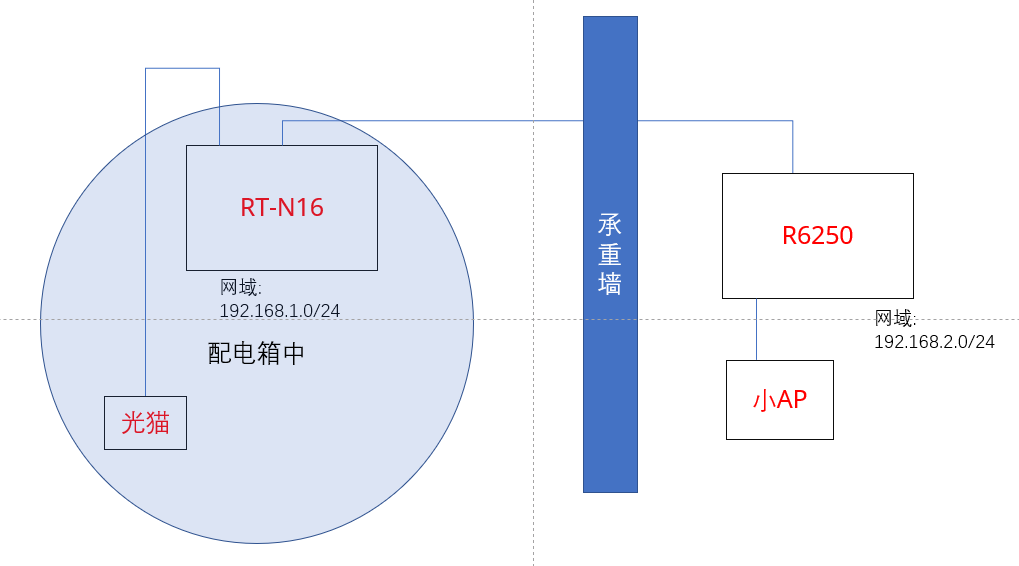
数字视频编码的发展历程
大家久等了,这是多媒体文件格式系列课堂文章的第三篇,前面已经讲过了容器与音频编码,现在我们要看到最为复杂的视频编码了,人们一直在想尽办法提高视频编码的效率,让它在尽可能小的体积内提供最好的画面质量,从而满足人们对于视频传输、存储的需求。和前两篇文章中介绍的容器与音频编码不同的是,视频编码有一条较为清晰的发展脉络,比种类繁多且不统一的音频编码要容易理顺,目前国际通行的视频编码标准基本上都是由MPEG(动态图像专家组)和ITU-T(国际电信联盟电信标准化部门)等组织牵头开发的,另外还有一些零星的编码,它们可能在一段短暂的时间内占据主流地位,不过最终还是让位于国际通行标准。
国际上主要通行的编码标准为ITU-T组织的H.26x系列视频编码和MPEG组织制定的部分编码标准,有一点需要说明的是,同样的一个标准在不同组织那儿可能会叫成不同名字,比如最典型的就是AVC(高级视频编码),大家可能更熟悉它的另一个名字——H.264,AVC是MPEG组织在标准中给它起的名字,MPEG组织从属于国际标准化组织(ISO)和国际电工委员会(IEC),所以在ISO标准中,它的正式名字是“MPEG-4 Part 10, Advanced Video Coding”。这种情况多见于H.26x系列编码,下文会注出。
而在这条主要脉络中,基本上囊括了接近半个世纪以来,视频编码的技术发展,我们将主要沿着H.26x以及MPEG这条主要脉络,为各位读者简单梳理出一条视频编码的发展历程。
为什么我们需要对视频进行压缩编码?
很简单,就是为了减小视频占用的容量大小。
数字视频实质上就是一帧帧连续的图像,虽然一帧图像的大小并不大,但每秒至少得有24帧图像(一般情况),它们累计起来就会占据非常大的空间,我们没有那么多的地方存储原始数据,那么只有一条路可以走,对它进行压缩。而视频的编码过程就是这个压缩过程,但与音频一样,在传统数据压缩算法来看视频文件里面基本上是没有什么冗余信息的,所以人们就有必要去开发针对视频的压缩算法,把实际存在的冗余信息给去掉,从而减少它的数据量,达到减小占用容量的目的。因此,目前的视频编码基本上都是有损的,意味着编码过后的视频在画面质量上会有损失。
前蓝光时代的视频编码发展之路
让我们首先沿着国际标准,按时间顺序来看看视频编码是怎么一步一步“现代化”的。
在模拟电视和胶片电影时代,我们看到的内容都是模拟信号还原出来的。但随着人们的需求不断提高,和计算机、网络的蓬勃发展,我们需要新的、能够承载视频内容的数字编码,用来支持视频内容在互联网上的传输,或是将其存储在数字化的存储设备中。
在上世纪七十年代末八十年代初的时候,人们已经研究出了不少新的针对图像等多媒体内容的压缩算法,此时开发数字视频编码的条件已经基本成熟,而第一个开发出实际编码的,就是后来在数字视频编码领域中起领头作用的视频编码专家组(Video Coding Experts Group),他们是当时名字还是“国际电报和电话咨询委员会(CCITT)”的ITU-T(国际电信联盟电信标准化部门)组织下面的专家组。这个编码被命名为H.120,它诞生于1984年,是一种偏向于实验性质的早期编码,主要基于差分PCM编码,用来保存电视内容,但是它并没有大规模的实际运用。
H.261:引入各种特性,奠定现代视频编码基础
在制定完H.120过后几年,VCEG并没有停止他们在视频编码上面的研究。此时很多跨国公司已经使用网络进行视频会议的需求了,在互联网带宽尚不充裕的年代里,人们需要新的视频编码来实现流畅而优质的实时视频通信,H.261就应运而生了。
H.261与首个数字视频编码标准H.120并没有直接的继承关系,它可以说是完全另起炉灶的一种编码。在针对图像的压缩算法上,H.261使用了我们现在比较熟悉的离散余弦变换(DCT)算法, 它在后来的JPEG编码中起主要作用。但不止于此,它引入了一系列针对视频的特性,奠定了现代视频编码的基础,其中主要有宏块(Macroblock)和基于宏块的运动补偿(Motion Compensation)。
宏块与基于运动补偿的帧间预测
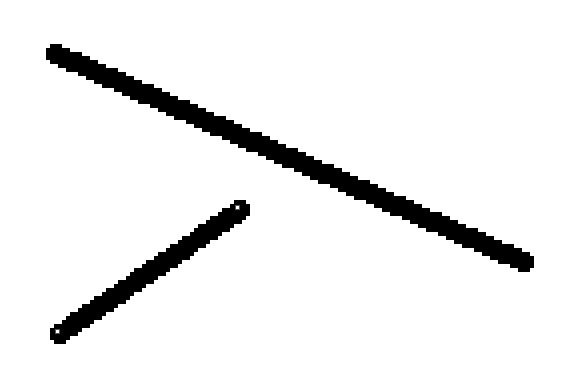
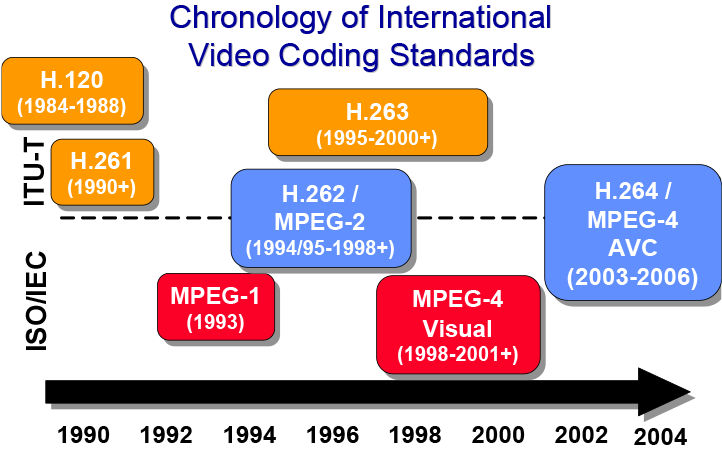
我们知道,视频是由一帧一帧的图像组成的组合,一般情况下一秒钟的视频中会包含24、25、30、60或更多张图片,它们按照一定的时间间隔播放出来,基于视觉残留原理形成了流畅、会动的画面。在连续的几帧之间,实际上存在着大量重复的画面,比如说下面这个例子:
 一个白色台球在绿色桌面上面运动
一个白色台球在绿色桌面上面运动
用小球运动的方向和距离来描述图像的变化
如果是以传统的思路对每一帧图像做压缩的话,显然整个视频在压缩过后仍存在大量的冗余。那么怎么办呢?H.261标准引入了宏块的思维,它将整个画面切分为许多小块,然后再引入基于运动补偿的帧间预测——画面的大部分都是不动的,那么我们将不动部分的区块沿用之前的压缩结果,动的部分用运动方向加距离这样一个矢量来描述不就可以节省出大量的存储空间了吗?
DCT算法
 将8x8个像素分成一个块
将8x8个像素分成一个块
![]()
DCT算法起源于上世纪70年代,到了80年代中后期,有研究者开始将其用于图像压缩。这种算法可以将图像从空间域转换到频率域,然后做量化——减少人眼敏感程度较低的高频信息,保留绝大部分低频信息,从而减少图像的体积。最后再用高效的数据编码方式将处理过后的数据进一步压缩,这里使用了Zig-Zag扫描和可变长编码。
注:图像的高频部分存有很多细节信息,而低频部分则存有轮廓等覆盖范围较大的信息。

 亮度通道做DCT变换后的图像,可以看到上方颜色连续部分非常平坦,而下方则拥有诸多细节
亮度通道做DCT变换后的图像,可以看到上方颜色连续部分非常平坦,而下方则拥有诸多细节
在H.261及之后基于H.261框架的视频编码中,DCT算法主要针对的是关键帧的压缩,所谓关键帧,就是在运动补偿中作为基准参考的一帧。打个比方,就像Flash动画中的关键帧一样,它定义了一个起点,后续的几帧都是基于这个关键帧演算出来的。因为它只做帧内压缩,不涉及其他帧,又被称为Intra-frame(帧内编码帧),简称I帧。
小结:创立混合编码框架,有里程碑意义
H.261设计的目标是编码出比特率在64~2048kbps范围内的视频,以用于实时的视频电话等应用。它首次确立了帧内预测与帧间预测同时使用的编码框架,在消除每一帧本身存有的冗余外,消除了帧与帧之间的冗余信息,从而大幅度降低了码率,成为了实际可用性相当高的一种视频编码。而它的编码框架也影响到了之后几乎所有的视频编码,尤其是H.26x和MPEG家族。
需要说明的是,H.261只是规定了该如何解码,只需要编码器最终产生的视频流可以被所有H.261解码器顺利解码即可。至于你前面怎么编码的,具体用的算法如何不同都没有关系,这点适用于之后几乎所有的视频编码。
MPEG-1 Part 2:引入帧类型概念,成为VCD标准
几乎在H.261开发的同时间,1988年,ISO和IEC两大国际标准化组织建立了MPEG(动态图像专家组,Moving Picture Experts Group)以开发国际标准化的音视频压缩编码。他们在1992年11月份完成了MPEG-1整套标准的制定,其中的第二部分标准化了一个新的视频压缩编码,它受到H.261的深刻影响,继承和发展了分块、运动补偿、DCT算法等思想,并做出了自己的改进,比如引入新的双向预测帧、亚像素精度的运动补偿等新技术。
引入双向预测帧(B帧)
H.261引入基于运动补偿的帧间预测算法之后,视频中的帧其实就已经分成两类了,一类是完整的,称为关键帧(Intra-frame),它就是一张完整的静态图像,可以直接被解码出来。另外的帧则是通过运动补偿算法在关键帧之上计算得到的。
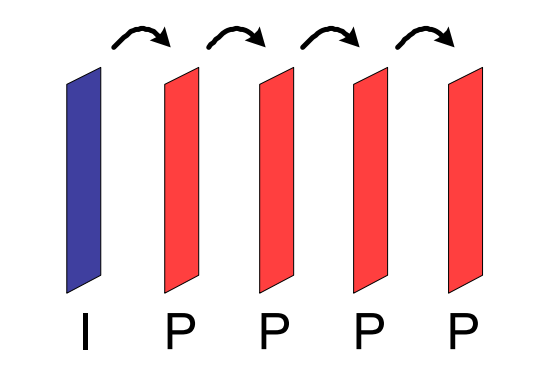
MPEG-1 Part 2引入了帧类别的概念,原来的关键帧被称为“I帧”,基于帧间预测计算得到的帧为P帧。在这两种H.261已有的帧类型外,它引入了一种新的帧:双向预测帧,也叫作B帧。
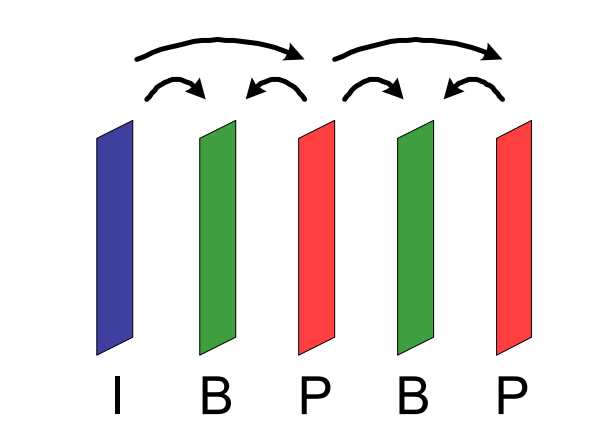
原本的P帧只能够前向预测,也就是说,它只能够基于前一帧计算得到。双向预测,顾名思义,它可以用前面的一帧作为自己的参考,也可以用后面那帧来进行预测。由于参考了更多的信息,B帧自身就可以包含更少的信息量,其压缩比自然就要比只能做单向预测的P帧还要高了。但是,B帧的引入带来了一个新的问题,即编解码难度上升了。
引入帧序列(Group of Pictures)
帧序列是一些按顺序排列的图像帧的组合,简称为GOP。一个GOP的头部是一个I帧,也只会有一个I帧,它包含了该GOP的基准参考图像信息,其后是数个P帧、B帧,它们都是以开头的I帧为基础,经过计算得到的。
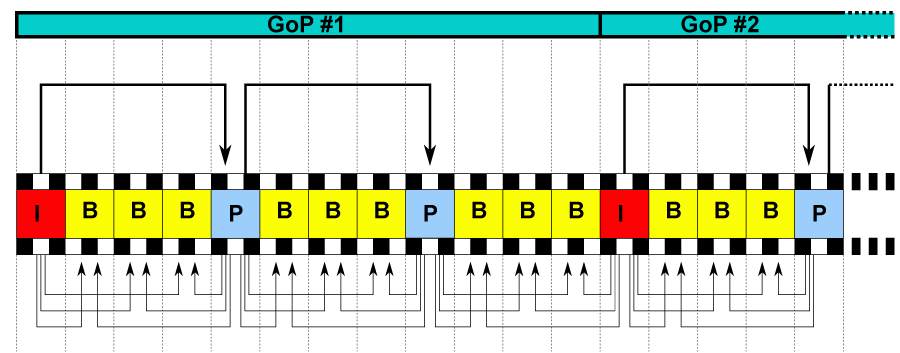
上面的图片就描述了一个完整的GOP,可以看到一个I和P帧之间隔了三个B帧。实际应用中,B帧确实是数量最多的帧类型。

亚像素精度的运动补偿
H.261中引入的帧间预测精度为像素级的,对很多分块的运动瞄准是不精确的,这点在MPEG-1上得到了有效改进。他们引入了亚像素级别的运动补偿,可以以1/2像素级别描述像素块的运动。
![]()
小结:成功接棒
MPEG-1成功地继承了H.261的技术框架,并对其进行了有效的补充,从而达成了不错的压缩比。在那个人们普遍还在用VHS录像带的年代里,MPEG-1已经能够以1~2Mbps的码率提供类似于VHS录像带的画质了。这也使得它被选用为VCD的标准,在世界范围,尤其是在我国风行十余年。
不过MPEG-1主要面向低码率应用,但实际上它在高码率下的表现也不差,于是,MPEG很快推出了它的升级版本,也就是MPEG-2。
MPEG-2 Part 2/H.262:DVD与(前)数字电视标准
1994年推出的MPEG-2中标准化了一种新的视频编码,它在1995年被ITU-T接纳为H.262,在这里我们简单称它为MPEG-2。相对于1993年推出的MPEG-1,它并没有太大的改动,主要是针对DVD应用和数字时代进行了改良。
支持隔行扫描
隔行扫描放在今天也并不是过时的概念,在九十年代初期,这种扫描方式有效降低了视频传输所需的数据带宽。平常我们看到的视频画面大部分都是逐行扫描(Progressive scan)的,比如说视频的垂直分辨率为1080像素,那么每帧画面的垂直分辨率就是1080像素。
而隔行扫描,顾名思义就是隔一行扫一次,它将每一帧画面拆分成两个场,每个场保留原有帧一半的信息。这种扫描方式在保证画面流畅度的同时降低了对传输带宽的需求,被各国的电视广播系统采纳使用。MPEG-2在制定时充分考虑到了数字电视系统的需求,加入了对隔行扫描的支持。
面向高码率和标清、高清晰度
从上世纪90年代开始,数字电视系统逐渐开始普及,它带来了更大的传输带宽。同时,DVD标准也快要尘埃落定,它提供了比CD大几倍的容量,能够承载更为清晰的画面。因此,MPEG-2提升了自己的目标码率范围,从MPEG-1时代的12Mbps实际豪爽地倍增到610Mbps,甚至在高清时代,它能够用20Mbps左右的码率传输高清画面。
小结:曾经最为通用的视频编码
MPEG-2虽然没有加入太多新的特性,在压缩率方面实际没有太大的提升,但由于它被选中成为DVD-Video、数字电视、DV等等一系列应用的标准编码,顺利地成为了世界范围内通行的视频编码格式,时至今日,它仍然被大量地应用在数字电视等系统中。
H.263:FLV与3GP的好搭档
原先的H.261和MPEG-1都是偏向于低码率应用的,随着互联网和通讯技术的飞速发展,人们对网络视频的需求在提高,在低码率下追求更高质量的视频成为了新的目标,而作为通信业的一大标准制定者,ITU-T在1995年推出了H.261的直接继承者——H.263。
H.263有多个版本,在1995年推出的初版中,它主要引入了在MPEG-1上开始应用的亚像素精度运动补偿,同样支持到1/2像素的精度。另外它改进了使用的DCT算法,加入了新的运动向量中值预测法,在编码效率上相比H.261有较为明显的提升。
需要注意的是,以上特性仅仅是它的基础部分,只需要实现这些新东西就算是支持H.263了,但它还给出了一系列额外的、用于增强压缩率的特性,比如说,在MPEG-1中新增的B帧,到了H.263中成了额外的PB帧。
H.263是一个被不断升级的编码,在初版之后还存在H.263+和H.263++两个官方升级版。在H.263+中,它着重提升了压缩率,相对初版有15~25%的总体提升。同时在2001年的修订中,它还引入了“Profile”的概念,将各种特性分成几个级别,完整支持某一级别的特性即为支持此Profile,比如说,初版H.263的基础部分是它的“Baseline”Profile。
H.263在互联网和通信业中得到了广泛的应用,它一度活跃在各种视频网站上面,和Flash播放器一起撑起了互联网在线视频的一片天,而在通信业中,被3GPP组织采纳成为多种通信标准中的标准视频编码,比如说MMS——也就是彩信。
另外它还被MPEG组织参考,作为MPEG-4 Part 2的基础。
MPEG-4 Part 2:特性很多,实现很多
在MPEG-2之后,MPEG组织有了新的目标——开发一套压缩率更高的编码框架,但同时保留对低复杂性的支持。1998年,MPEG-4标准正式诞生,其中第二部分定义了一套新的视觉编码体系,是的,它并不是仅仅针对于视频应用,而是广泛意义上的视觉(Visual),故也被称为MPEG-4 “Visual”。
它的核心设计实际上与H.263趋同,但是包含了更多关于编码效率的增强。它定义了复杂度不同的多种Profile,从最基本的Simple Profile到非常复杂的Simple Studio Profile,前者不支持B帧,而后者甚至支持到4K分辨率和12-bit、4:4:4采样的编码。
尽管MPEG-4 Visual是一个野心勃勃的编码,但它遭到了业界的冷待和批评。一个是它的压缩率相比起MPEG-2并没有重大提升,而因为授权和专利费用问题,很多厂商选择自己去实现一套兼容MP EG-4 Visual的编码,而不是直接采用标准,这其中就有经典的DivX和Xvid两兄弟,微软也拿它作为Windows Media Video的基础,一点点升级到WMV9。
其他编码
时间已经来到二十一世纪,高清视频和高清电视开始普及,新的应用带来了更高的需求,迫使业界开始研究新的更高效的视频编码,我们熟知的AVC即将登场,不过在介绍它之前,我们先来看看其他几个有较多应用的视频编码。
MJPEG
JPEG想必大家都很熟悉,这个MJPEG跟JPEG之间有着千丝万缕的关系。视频不是一帧一帧的吗?那每一帧都用JPEG进行压缩,然后组合起来不就行了吗?是的,MJPEG就是一个JPEG图像组合,每一帧包含了完整的图像信息,正因为如此,它的压缩率并不高,但是实现起来简单的特点让很多数码相机厂商将它作为相机的视频编码,实际上它得到了相当广泛的利用。
RealMedia
对于国人来说,RealMedia绝对是一个带有情怀的词语。他们家的RM系列编码在十多年前在国内网络上曾有相当的覆盖度。实际上它的实现基本上都是参考同时期的国际标准而来的,比如说清晰度和压缩比都很高,压过同时期DivX一头的rv40是参考了H.264而形成的。
RM最大的问题还是支持范围不广,在浏览器中播放RM需要插件,基于Flash播放器的视频网站的兴起也让它的用途逐渐变得狭隘,最终在正版H.264的冲击下,RM慢慢的销声匿迹了。
WMV
微软有自己的客厅梦想,除了Xbox以外,他们想让PC走进客厅,当然这都与Windows Media Video无关。微软基于MPEG-4 Part 2创造出了一系列新的编码,起初它们都被称为Microsoft MPEG-4或是Microsoft ISO MPEG-4,但很快,微软将其归入了Windows Media家族,首个版本是WMV7。
接下来微软在WMV7的基础上面不断加入自家的东西,使得它能够适应更高分辨率的视频,最后,他们在WMV9中加入了新的Profile,产生了新的VC-1编码。
蓝光时代标准之争
在DVD普及之后,高清视频的时代很快就到来了。人们很快发现,就算是双层DVD,其容量对1080p视频来说,也是完全不够用的。很快,大公司开发出了两种新的以蓝光为激光束的光盘,一种是以DVD论坛为首开发的HD DVD,另一种是Sony牵头另起炉灶的Blu-ray。两种光盘格式的战争我们按下不表,这里要讲的是,伴随着新光盘制式一起出现的全新视频编码标准——VC-1和H.264。
AVC/H.264:集大成者一统江湖
HD DVD和Blu-ray的标准里一共支持了三种视频编码,其一是古老的MPEG-2,其二是微软主推的VC-1,最后一种就是全新的AVC。别看它的名字很简单,其实它大有来头,是MPEG和ITU-T两个组织联合推出的新一代国际标准,在MPEG那儿被规范为MPEG-4 Part 10 Advanced Video Codec,在ITU-R那儿它又被标准化为H.264。
对于H.264这个名字,我想大家应该都不会耳熟。但就是这个现在我们每天都能够接触到的视频编码格式,曾在十多年前引发了一场软解危机,将当时很多主流CPU挑落马下,也使得ANI三家都在自己的产品中加入了辅助解码的硬件加速单元,不过这与我们的主题没什么关系,暂且按下不表。这里要讲的,还是H.264的厉害之处,究竟它用了什么手段能够在编码质量上面实现飞跃,从而独占市场十余年时间还没呈现衰退迹象。
总结下来主要有如下的几点:更灵活的宏块划分方法、数量更多的参考帧、更先进的帧内预测和压缩比更高的数据压缩算法。
更灵活的宏块划分方法
之前的标准中,宏块的划分方法是固定的,以16x16个像素为一个宏块。不过在新时代,这种粗放的划分方法不够灵活,于是H.264同时允许16x8、8x16、8x8、8x4、4x8和4x4这些精细度更高的划分方式。同时H.264将亚像素精度的运动补偿描述从1/2像素精度细化到了1/4的程度。这样一来,在帧间预测中新的编码拥有更高的精准度,但实际的数据量并不会增加太多,提高了压缩率。
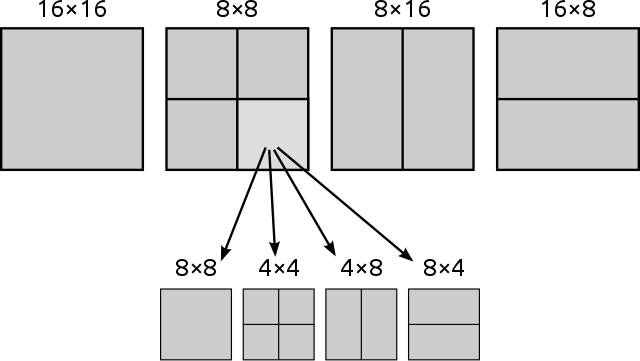
数量更多的参考帧
在以前的标准中,每个B或P帧可参考的帧数是有限且数量过少的,H.264一举将限制放松到了16帧的程度,在大部分应用场景中,每帧的可参考帧数量至少都有4~5个,而在之前的标准中,P帧仅能参考1帧,B帧则是2。这一特性可以提高大多数场景的画面质量,或是降低体积。
更先进的帧内压缩
 每个宏块包含的预测模式信息
每个宏块包含的预测模式信息
对于I帧,H.264也引入了新的压缩方式。一般来说,对于图像中的某一像素点,它与附近相邻的像素的颜色是差距不大的,所以我们就可以利用这个特性进一步缩小单帧图像的大小,怎么利用呢?H.264将单个宏块内的像素颜色变化规律规范成了公式,编码时只要写此处应用哪个公式就行了。当然这里我表述的较为简单,完整的帧内预测还是非常复杂的,H.264对4x4的宏块规定了9种预测模式,对16x16的亮度平面宏块规定了4种可用模式。大大减少了单帧图像的数据量,同时保持了很高的图像质量。
 差分图像加上预测信息可以还原出原始图像
差分图像加上预测信息可以还原出原始图像
CABAC
在编码的最后阶段,对数据进行无损压缩时,H.264除了支持在H.261中就存在的VLC编码外,新增加了两种无损数据压缩编码,一种是VLC的升级版——CAVLC,另一种是复杂程度更高的CABAC(前文参考之适应性二元算术编码,Context-based Adaptive Binary Arithmetic Coding)。

CABAC也是一种熵编码,主要原理也是用长编码替换掉出现频率少的数据,而用短编码替换出现频率高的数据,但它引入了更多统计学优化,并且具有动态适应能力。虽然在解码时需要更多计算,但它能够比CAVLC节省更多的数据量,通常能有10%。
小结:巨大的改变带来的是巨大的成功
除了以上介绍的几点外,H.264还有非常多的新特性,与MPEG-4 Visual不同的是,这些新特性有效地帮助H.264在节省容量方面取得了重大进展。这里我举一个有强烈对比的例子,DVD Video标准的视频,采用的是MPEG-2编码,码率约在9Mbps左右,但它的分辨率仅为720x480,而且在某些场景下我们可以很明显看到有损压缩产生的破坏;而同样的码率,放在H.264上面,已经可以承载起1080p的视频,并且拥有良好的质量。
除了在编码效率上有重大提升外,H.264针对网络传输的特性对编码组织方式进行了优化,让它更能够抗丢包,抗干扰。在种种手段之下,它成为了近十年来统治视频领域的编码,并且可以说它已经成为了HTML 5中的事实标准,现在你很难看到一件不支持H.264编码的设备,从手机到摄像机,从流视频到蓝光光盘,它的应用范围广,效能强,即使在新编码已经出现的当下,它仍然有很强的生命力和不可替代性,可以预见的是,H.264将在未来一段时间内继续统治视频编码领域。
VC-1:失败的挑战者
进入高清时代后,微软也顺应潮流,为WMV9进行了升级,加入了针对高清视频的新特性,让它能够胜任1080p级别的高清视频,新的编码即为VC-1。与H.264相比,VC-1总体的复杂程度要低一些,也因此在软解上对CPU更加友好。实际上VC-1也通过了国际组织SMPTE的标准化。
VC-1与HD DVD有一定的捆绑关系,在蓝光大战初期也通过这种方式得到了一定的推广。然而,随着HD DVD阵营的认输,VC-1也随之销声匿迹,很难再看到了。
UHD与流媒体时代,新的编码兴起
H.264很强大,但是它在超清时代有点不够用了。随着视频分辨率的跨越式提升,H.264表现出了疲态,它在应对4K视频时已经没有办法提供很好的压缩比了。很明显,人们需要新的编码来继承它的位置,而它的直接继承者——HEVC,在经过多年研究之后,终于在2013年被通过了。
HEVC/H.265/MPEG-H Part 2:视频编码王位继任者
HEVC,全称高效视频编码(High Efficiency Video Coding),同样的,它也是由MPEG和ITU-T联合制定的国际标准编码。被包含在MPEG-H规范中,是为第二部分(Part 2),在ITU-T那儿,它是H.26x家族的新成员,为H.265。
HEVC主要是针对高清及超清分辨率视频而开发的,相比起前代AVC,它在低码率时拥有更好的画质表现,同时在面对高分辨率视频时,也能提供超高的压缩比,帮助4K视频塞入蓝光光盘。
代替宏块的编码树单元
HEVC引入了新的编码树单元(Coding Tree Units)概念,取代掉了存在于视频编码中多年的宏块概念,它的单块面积大了许多,达到了64x64,但仍然保留了可变大小和可分割特性,最小单元为16x16。单个编码树中包含了小的编码单元,它们可以由四分树形式呈现,并很快地可以确定下其中的单元是否可被再分割,内部编码单元最小可以被分割为8x8大小,精细程度仍然是非常高的。
单个编码单元也可以继续被切割、分类,可以成为预测单元(Prediction Units),后者可以指示该单元的预测形式,是画面内预测还是画面间预测或者甚至是根本没有变化、可以被跳过的单元;也可以成为转换单元(Transform Units),它可以做DCT转换或是量化。
编码树单元的引入让HEVC既可以用大面积单元来提高编码效率,也可在需要的时候细化,保留更精细的细节。所谓该粗略的地方就粗略,该精细的地方就精细,HEVC在它的帮助下让码流的效率更高。
更高效的DCT
既然分块的最大面积大了,那么DCT算法也需要跟上才行,HEVC将DCT算法的最大尺寸扩大到了32x32的地步,对于图像中变化较为平坦的部分,它有着更高的压缩率。
33种帧内预测方向
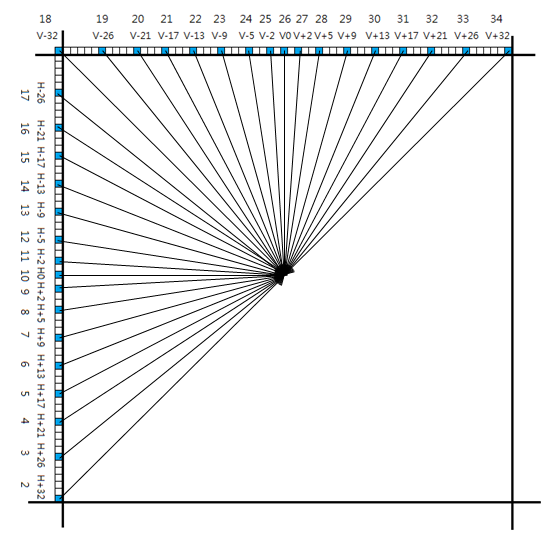
还记得上面写到H.264为4x4宏块引入了9种帧内预测方向吗?HEVC直接把这个数字提升到了33种,在静态图像的压制上不仅实现了更高的效率,也实现了更高的精度,这也是它成功杀入静态图像编码市场的一大利器。虽然编码难度变高了,但只要用硬件编码器就没有那么多问题。
小结:高效编码,但受困于高额专利费用
相较于AVC,HEVC在高分辨率下的编码效率又有非常大的提升,举个实例,同样一段4K视频,使用H.264编码的大小可能会比使用HEVC大出个一倍。这种巨大的进步幅度也使得Blu-ray直接用它作为标准编码,推出了UHD BD,而它在单帧图像压缩上面的改进也让它拥有胜过JPEG的能力,于是我们看到在移动端,越来越多的设备选择将其作为默认的视频、照片输出编码。
但是相比起AVC,HEVC的推广速度慢了很多,一个是它的编解码难度比H.264高了太多,但这点通过各路硬件编码器和软件优化逐渐化解掉了,目前常见的设备基本上支持HEVC的硬件编解码;第二个就是HEVC高昂的专利费用问题,它并不是一个免费的编码格式,虽然个人使用它完全没有问题,但对于想要兼容它的厂商来说,这笔高昂的专利费用足以让他们却步,尤其是崇尚自由开放的互联网市场。于是,我们看到众多厂商选择了免费开放的VPx系列编码,以及系列的后继者——AV1。
VPx系列与AV1:以免费为卖点
VPx系列编码实际上已经有很长的历史了。它的前身是On2 Technologies公司的TrueMotion系列视频编码,在开发TrueMotion VP8编码时,公司被Google收购了。在Google的介入下,VP8从原本的专有技术变成了开放技术,在BSD许可证下面进行开源。
从技术角度来说,VP8采用的技术是类似于H.264的。虽然在我们看到的宣传中,VP8拥有比H.264更佳的压缩效率,但在实际应用中,由于它在设计上有一定的瑕疵,表现并不如H.264,最终它虽然进入了Web标准,但也没见有人用它,反而是由它的帧内压缩技术提取而成的WebP受到了欢迎。
VP8的表现并不理想,Google很快就推出了它的继任者——VP9。这次,他们参考的是HEVC,设计目标同样是高分辨率下的高效编码。VP9中的一些设计是受到了HEVC的影响的,比如说同样最大为64x64的超级块(Super Block)。最终VP9达成的结果是提供了比VP8高达50%的效率提升。看起来它能够和HEVC比肩了,但是它也遇到了和VP8相似的问题,推广不开。VP9的应用范围实际也局限在Google自家的Youtube中,只能说是缺少实际应用场景。
但很快,一些厂商认识到HEVC高昂专利费用带来的弊端,他们决定创立一个开放联盟,推广开放、免费的媒体编码标准。这个联盟就是开放媒体联盟(Alliance for Open Media),创始成员有Amazon、Cisco、Google、Intel、Microsoft、Mozilla和Netflix这些我们熟悉的大公司,而后加入的还有苹果、ARM、三星、NVIDIA、AMD这些同样耳熟能详的公司。
Google将他们还在开发中的VP10贡献了出来作为联盟新编码的基础,很快,名为AV1的编码诞生了。在Facebook的测试中,它分别比VP9和H.264强上34%、46.2%,这次看上去是真的达到HEVC的级别了。
在这两年中,AV1也确实开始得到厂商们的重视,比如说最近Netflix已经确定了要使用AV1作为主力编码,而Intel也推出了开源免费的SVT-AV1编码器,充分利用自家的AVX-512指令集。但是这种联盟还是相当松散的,比如说联盟成员之一的苹果,目前对AV1根本是无动于衷,旗下设备中全部转向HEVC。
不过从Netflix决定使用AV1作为主力编码这种态度来看,AV1免费、开放的特性还是具有相当的吸引力的。但目前在硬件方面是缺乏对它的支持的,不仅是PC端没有针对AV1做硬件解码,数量更多的移动设备也没有适配,前不久刚有一款宣传是首个加入对AV1硬件解码的SoC才发布。对比起硬件支持较为齐全的HEVC,这将是AV1推广之路上的一道槛。
未来编码:VVC
目前MPEG和VCEG已经开始研究HEVC的继任者了,目前我们知道的信息是,它暂时被命名为Versatile Video Coding(多才多艺视频编码),并将会成为H.266。它是面向于未来视频的编码,将会支持从4K到16K分辨率的视频压缩,并且支持360°视频,它的目标是在HEVC的基础上将编码效能提升一倍。
未来它可能加入的新特性有:更为复杂的编码单元结构;更大、更细致的区块划分;全局帧参考;更多的帧内预测模式(目前已经有65种)……在复杂度上面,相比HEVC,VVC将会直接高出一个维度。但是国际标准目前面对着以AV1为代表的开放标准的挑战,很难说他们会不会取消掉部分特性,从而将它正式发布的时间给提前。
总结:与时俱进
显示器、电视的分辨率越来越高,网络带宽越来越大,设备对于多媒体内容的处理能力越来越强,视频编码也一直随着时代的变化而不断进步着,但是它的框架从H.261开始就未曾有过重大的变化,只不过每个新编码都在这个既定框架下利用半导体性能的成长而加入新的更为高效的算法。比起进步并不明显的音频编码,新视频编码在带宽与容量上面提供的节约效果要明显得多了,甚至更新的编码在画质表现上也更有优势。在不远的未来,10-bit色深和HDR将会普及,在根本上取代掉还是上世纪标准的SDR内容,为我们带来更为精彩的视觉体验。诸如HEVC这样的编码实际早已做好了准备,在未来,它们的应用场景甚至将突破视频领域,就以新的苹果设备为例,HEVC实际已经成为它的标准编码格式,通行于图像和视频领域中。
另外,根据最新的报告,当前互联网流量中占大头的就是视频流量,随着流媒体继续深入日常生活,用于视频传输的流量只会更大,而互联网的总体带宽并不是可以无限提升的,对于内容提供方来说,流量费用也是相当一部分开销,压缩效率更好的编码自然也会受到他们的青睐。实际上,编码不断升级这件事情是双赢的,用户和内容提供方都可以从中获利。
由于时间与作者个人能力限制,本篇文章也存在诸多的不足,但我仍然想通过对这些编码的概述让更多人了解到正确的编码知识,如果能够起到抛砖引玉的作用,让更多人对编码产生兴趣,开始自己的研究,那是最好不过的事情了。
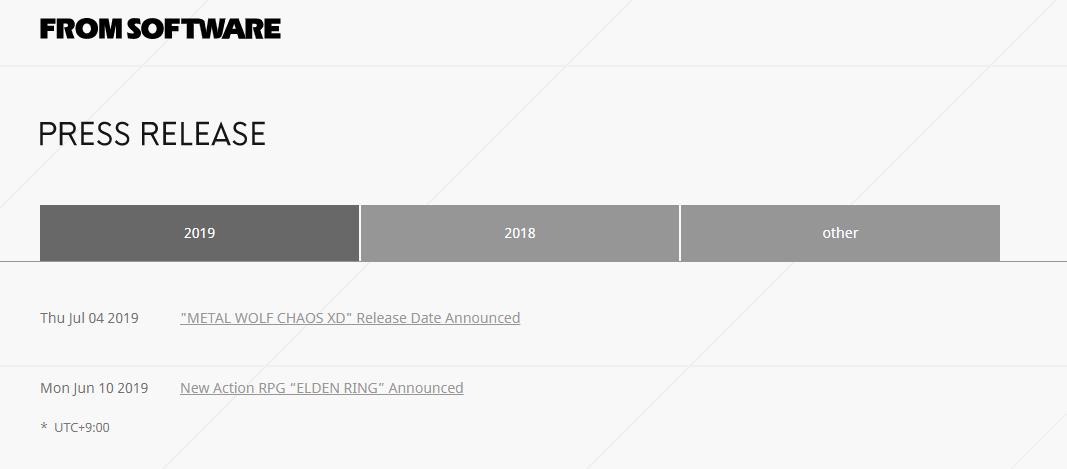 FromSoftware 的新闻稿页面
FromSoftware 的新闻稿页面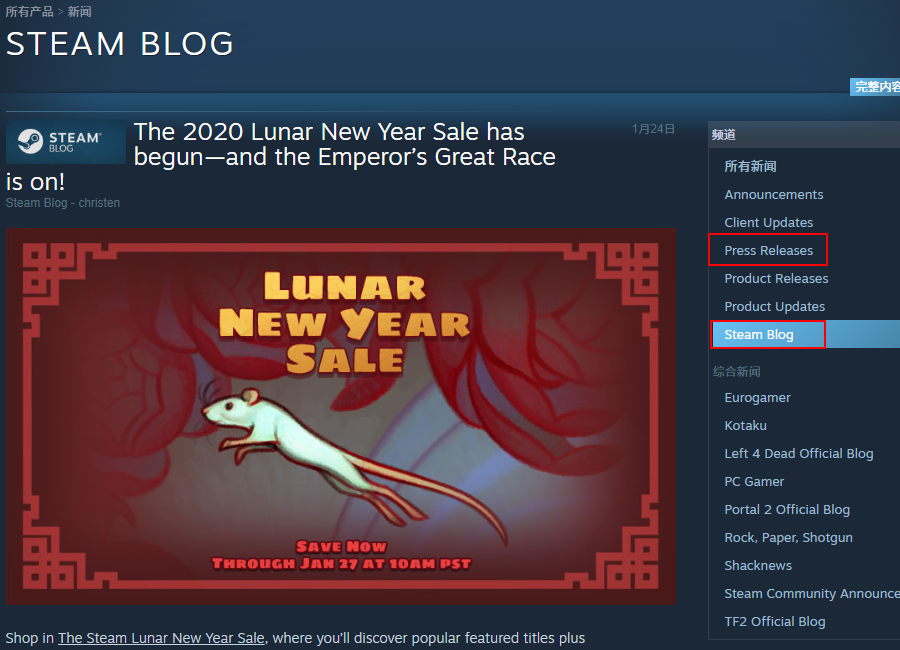 Steam 新闻页中的 Press Releases 已经很久没更新了
Steam 新闻页中的 Press Releases 已经很久没更新了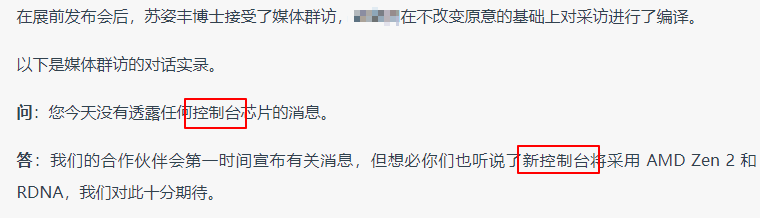 Console,一词多意,这里被错误翻译成了“控制台”
Console,一词多意,这里被错误翻译成了“控制台”
 到了某媒体那儿,流言提示就没了,变成肯定了
到了某媒体那儿,流言提示就没了,变成肯定了 不点名了,都是友媒
不点名了,都是友媒
 一些网站也会把 RSS 通道做到页面底部去,比如机核就是
一些网站也会把 RSS 通道做到页面底部去,比如机核就是