Intel是怎么失去自己的性能优势地位的?
要是有人在五年前跟我说,AMD的处理器性能逼近甚至超过Intel的,那我当时肯定会像看傻子一样看着对方,然后缓缓说出一句“你在搞笑吧?”来严肃回答对方。
然而,两年之后的现实就是,AMD用Zen 2架构的Ryzen 3000系列处理器在性能与口碑上都追上,甚至赶超了Intel,“AMD, Yes!”这句口号也是被喊得越来越响亮,甚至出现了什么状况呢?面对竞争对手的咄咄逼人,他们拿出了Comet Lake-S这种实质是Refresh的产品来应对,连已经被应用在移动端的新内核微架构都懒得换,加了两个核心,优化了下散热,提了点频率就拿出来卖了。
那么Intel是怎么一步一步走到今天这个局面的?我分析了从14年开始,Intel的产品布局还有他们的Roadmap,至少有一点可以明确的是,制程工艺,真的卡了Intel的脖子。从22nm到10nm的路上,每一次制程节点的升级都遇到了问题,结果就是Intel匆匆忙忙之间,不仅要为新制程的延期擦屁股,还要为竞争对手的突击来调整自己的产品布局。首先,我们要从14nm,这个可以说是一代经典的工艺说起,让我们把时间倒回到2014年。
14nm延期:Tick-Tock战略的终结
2014年的Intel,正在用着成功的Haswell和22nm制程称霸着x86处理器市场,他们原本计划在那年推出升级14nm制程的Broadwell,也就是Haswell的换制程版本,延续自己成功的Tick-Tock战略。
什么是Tick-Tock战略呢?这里为不清楚的朋友简单介绍一下。
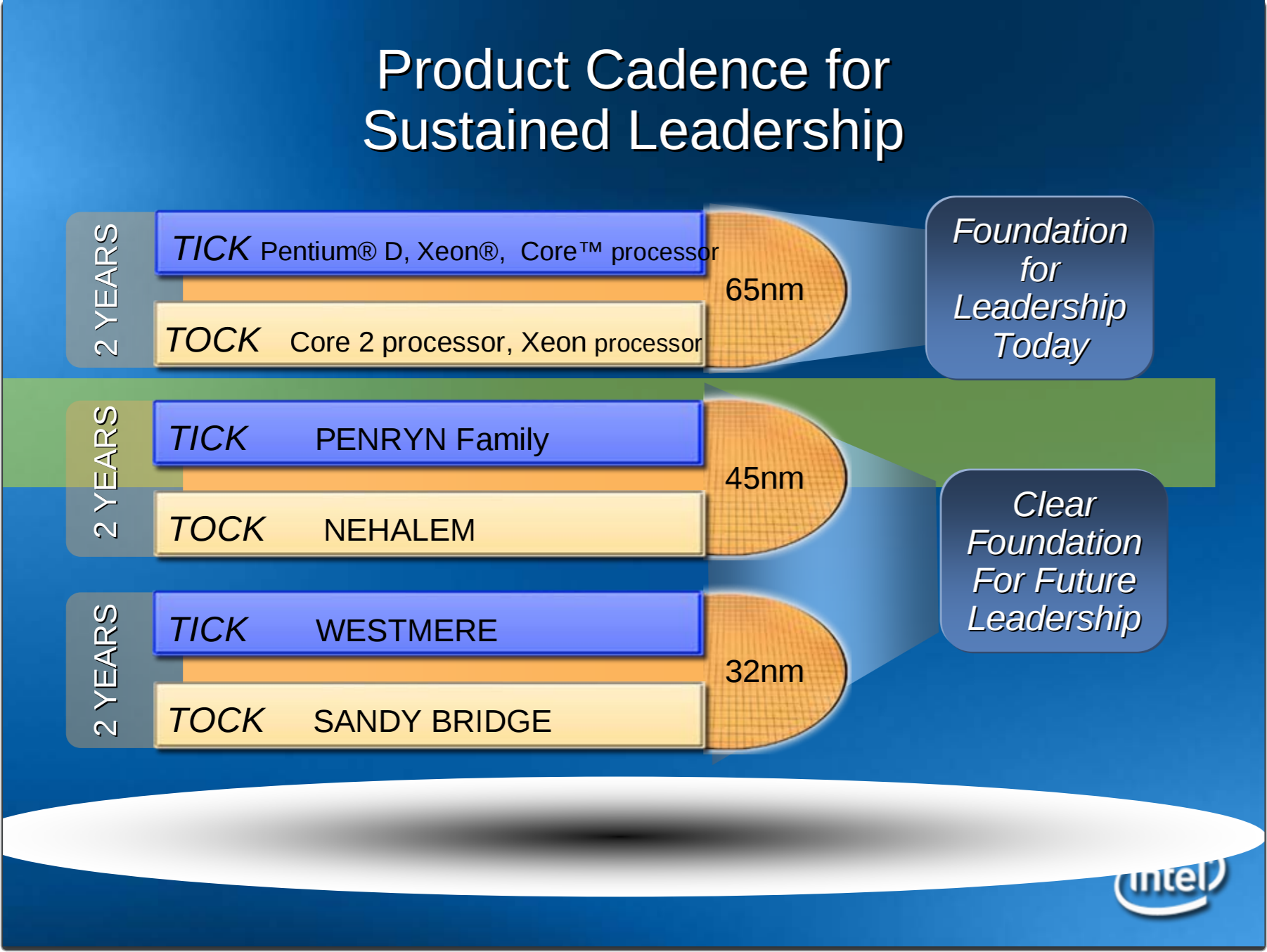
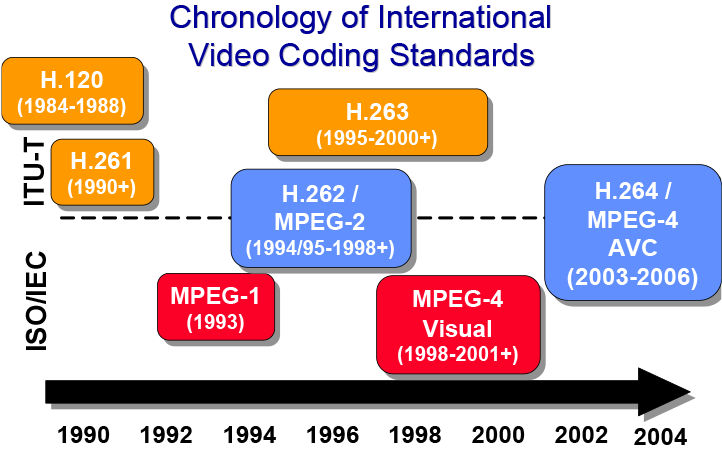
Tick-Tock战略是Intel在2007年提出的处理器更新战略,因其类似于钟摆运动而得名。在Tick年,Intel将会引入新的制程工艺,但不会对CPU微架构进行大幅改动;而在Tock年,Intel将会使用上年更新过后的工艺推出采用全新架构的CPU。这样,以两年为一个周期,Intel可以稳步推进自己的处理器更新换代,在市场上牢牢坐稳自己领导者的位置。
这套战略非常有效,Intel沿着Tick-Tock战略制定的轨迹,从2007年一路走到2013年,期间他们的制程工艺从65nm一路发展到22nm,而内核微架构也从Core 2 Duo时代的Conroe一路进化到2013年的Haswell。
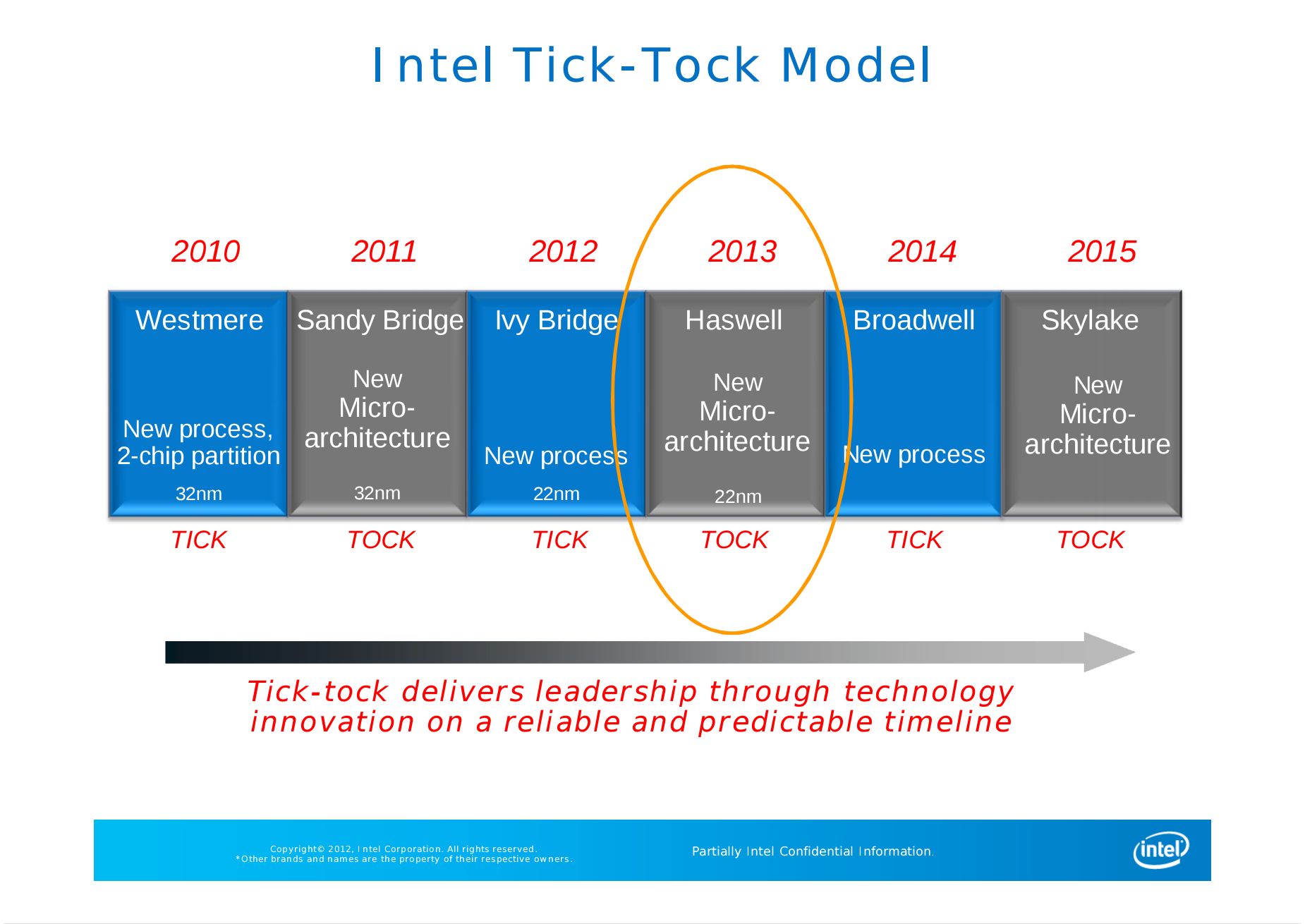
Haswell,也就是现在仍然被人们津津乐道的四代酷睿,一经推出就成为了当时的装机首选。一方面,它相对于上代处理器有可观的性能增幅,另一方面,竞争对手还陷在推土机架构的泥沼中,一时半会儿没有还手的力气。看起来Tick-Tock战略非常成功,下一年就可以推出采用14nm制程的Broadwell系列处理器了,但就在这个当口,制程工艺的更新出了岔子,跟不上了。
Intel为每一次的制程迭代都设定了相当高的目标,从22nm进化到14nm也不例外。但Intel再牛逼,也突破不了物理的极限,随着晶体管变得越来越小,单位面积内晶体管的数量越来越多,在没有对材料进行改进的前提下,漏电和发热情况会越来越明显,同时,新工艺早期的良率难以与老的成熟工艺相比,搞定这些问题需要时间。在2013年末的时候,14nm制程还没有成熟到能上正式产品的底部,在当时Intel期望能够在下一年的第一季度将其应用于量产,结果我们都知道了,预期没能实现。
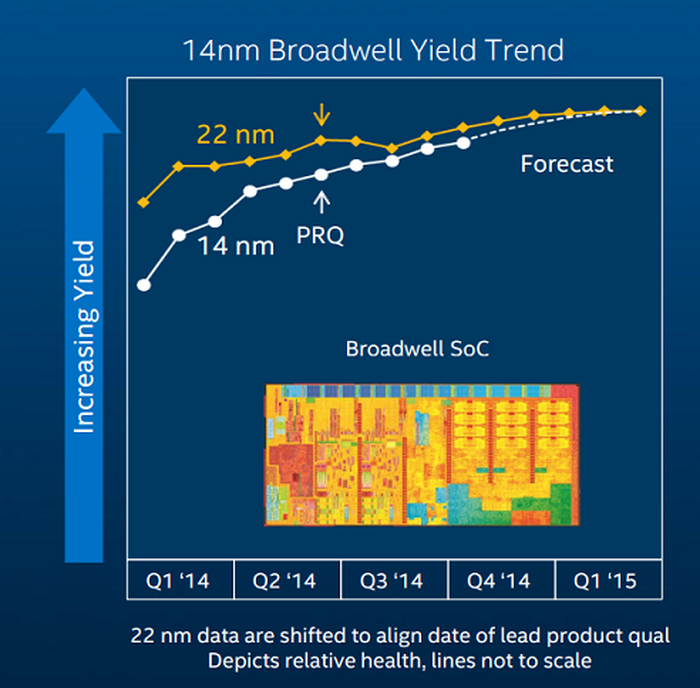
在2014年年中的时候,Intel对外解释了他们14nm制程延期的一些原因,上图主要诉说的是14nm制程的良率还没有22nm那么高,才刚刚满足Intel的PRQ(能够用于正式生产的良率点)。那工艺才刚刚进入量产,产能还跟不上怎么办?Intel很聪明,他们选择对现有产品在不进行制程升级的情况下进行小幅更新,也就有了Haswell Refresh这一代处理器,代表产品有Core i7-4790K和Xeon E3-1231V3等。从这里开始,Tick-Tock战略在事实上已经被改良的Tick-Tock-Refresh战略所取代,不过Intel暂时还没有承认这一点,继续使用既有的路线图走了下去。
在既有的路线图上面,2014年是Tick年,Intel应该换新的工艺,也就是预定的14nm推出新产品。但因为工艺出现了延期,没能很好地实现Tick年的预定计划,而新的Tock年——2015年很快就到了,按照计划他们应该推出采用新架构的14nm处理器。为了赶上原本的路线图,Intel直接砍掉了Broadwell的桌面版(实际只有两款且出货很少),在2015年的夏季,直接推出了Skylake处理器,也就是我们熟知的第六代酷睿。
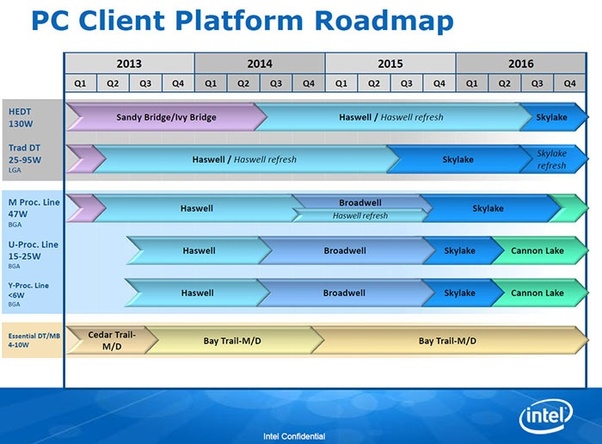
上图是Intel在2015年公布的官方路线图,可以看到的是,在桌面端,Broadwell完全消失了,接替Skylake的,是又一代的Refresh产品。而在移动端,Broadwell与Haswell Refresh并存,之后出现了一个需要注意的地方,那就是Cannon Lake,它将要在移动市场上接替Skylake,是Intel规划中的初代10nm处理器。按照这张路线图,Intel计划在2016年的第二季度将Cannon Lake带入市场,也就是说,在当时,Intel对2016年量产10nm处理器这件事情是非常自信的。
结果,在2016年,我们没有等来Cannon Lake和10nm制程,等来的却是Intel宣布将Tick-Tock战略由新的Process-Architecture-Optimization(制程-架构-优化,简称PAO)三步走战略替代的消息。
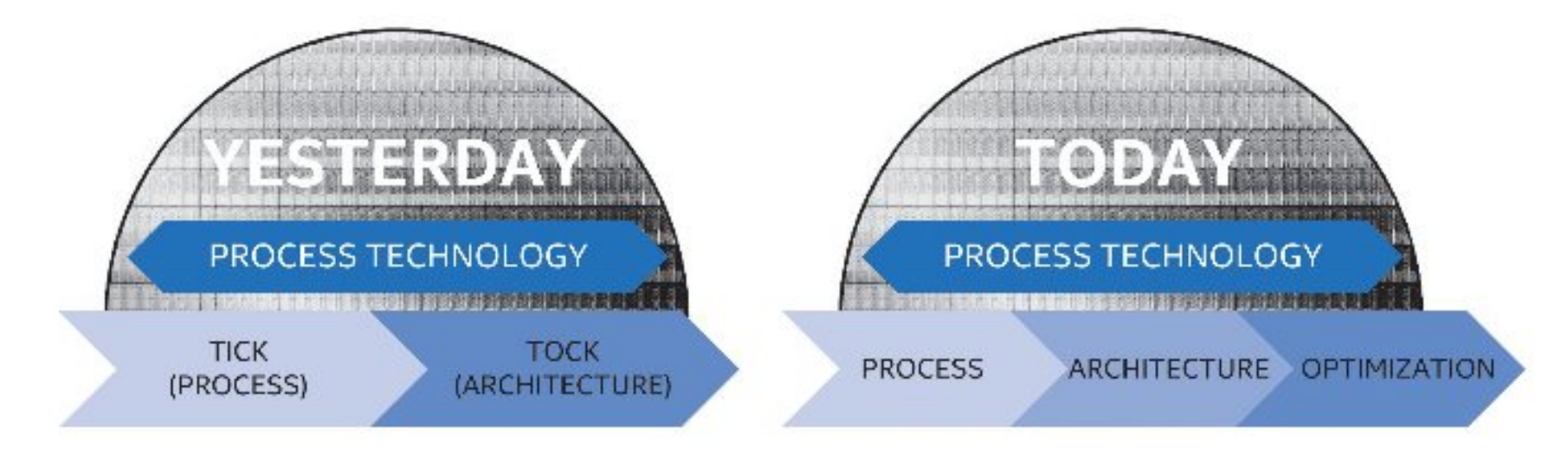
在新的PAO战略中,制程工艺仍然是开启一个周期轮回的首要因素。如果将14nm作为PAO战略的首个制程节点,那么Skylake处理器就是这一轮PAO中的架构改进点,正好是对应起来的,那么在Skylake之后带来的,就应该是Optimization,也就是原本的Refresh这一步,它将优化新架构和新制程的表现,提供一个PAO轮回中最好的综合表现。好了,Intel也就顺势公布了Skylake的下一代将会是Kaby Lake,而不是此前定下的Cannon Lake。
至此,Tick-Tock战略完全失效,被新的PAO战略所取代。但我们谁都没有想到,Intel的头一个PAO轮回就花了他们将近四年的时间。
10nm屡次延期:Cannon Lake夭折与不尽如人意的Ice Lake
上文说到,在Intel很早以前的路线图中,他们计划在2016年将10nm带到人们的眼前,结果事与愿违。不过Intel仍然没有放弃,因为他们深知,制程工艺的领先将会在竞争中给他们带来莫大的优势。于是在2017年伊始的CES展会上,Intel CEO在自家的发布会上面信誓旦旦地表示,他们的10nm处理器会在当年年末的时候出货。紧接着的投资者公开会上,Intel更是扔下了一枚炸弹,他们声称将会在数据中心产品上首先启用10nm制程,而不是像往常那样,首先在移动超低压产品上应用,但同时,他们还告知投资者,今年在消费级还会有一代14nm处理器。
这是为什么呢?我们把时间稍微倒回去一个月。
2016年12月13日,AMD在名为“新地平线”的峰会上面公布了自家传闻已久的全新Zen架构的正式产品——Ryzen系列处理器。在次年的3月初,初代Ryzen的首批三颗处理器正式开卖了,上来就是八核十六线程的规格,在多线程能力方面对Intel处理器造成了很大的威胁,这也被视为AMD走出推土机阴霾,重返高性能处理器市场的标志。
在接到蜇伏了多年的老对手突然出的一记重拳之后,Intel当然是要回应的,于是就有了上面的“今年在消费级还会有一代14nm处理器”,现在我们知道,Intel为了应对AMD的攻势,给桌面端沿用了多年的四核规格加了两个核心,推出了代号为Coffee Lake的八代酷睿,同时他们再次优化了在Kaby Lake上已经被优化过一次的14nm制程,命名为14nm++。

当然,Intel肯定是没忘记他们的10nm制程的,在当年三月份末的制造日(Manufacturing Day)活动上面,他们向各路媒体公开了10nm制程的细节和他们设定的目标,其中最为人印象深刻的是,他们要把晶体管密度提高约2.7倍,这样一来,Intel能够继续保持3.5年的制程领先,并且能够比台积电/三星/GF这几家的7nm工艺更加先进。
吹归吹,还是得拿出实际产品才能够让人信服。
整个2017年,Intel在10nm上再没了什么动静,甚至于在2018年的CES演讲上面,他们的CEO提都没提自家的x86 CPU,只有在演讲结束之后的一个面向媒体的短会上面,CCG(客户计算业务组)的高级副总裁在时长为10分钟的短暂演讲的末尾提了一句,称他们的10nm产品已经在2017年出货了。这种低调的声明对于Intel来说并不是什么常见的事情,在场的不少媒体意识到,Intel内部肯定有什么问题发生了。
结果到了2018年5月份,除了Intel自己意外泄漏的一份文档中出现了Cannon Lake之外,其他地方根本就没这系列的影子,说好的出货出哪儿去了?答案最终浮现是在中国市场上一款出货量并不大的新笔记本中:

从上面的广告Banner中,我们可以发现这款处理器的型号为Core i3-8121U,而它就是最初和最末的Cannon Lake处理器,整个Cannon Lake系列中唯一一款正式进入市场的处理器。
为了研究Cannon Lake和10nm工艺,各路硬件媒体马上从中国购买了这台笔记本回来,比如AnandTech的Ian Cutress博士就行动了,很多媒体随后都发布了对这款处理器的评测,其评价基调都差不多:失望。这款处理器在默认情况下基本上打不过规格类似的Core i3-8130U,甚至在同样的频率下面,作为拥有更先进工艺的处理器,它的功耗比Core i3-8130U还要大。
Cannon Lake被初代10nm工艺所严重拖累,以至于该系列仅推出了一款处理器就被Intel给砍掉了。为它配套的300系芯片组被修修改改用在了Coffee Lake身上,这也就是为什么,300系芯片组的代号是Cannon Point的原因。
Cannon Lake虽然夭折了,但它对Intel仍然有着莫大的意义。首先,它是一个新PAO轮回的起点,正式引入了新的制程,其次,在Cannon Lake上面,Intel完成了其处理器平台与内核微架构的解耦,以往Intel处理器的内核与平台共同一个代号,而在Cannon Lake身上,两者分离了。Cannon Lake搭载了Skylake微架构的升级版——Palm Cove,而在2018年初期,Intel就正式公布了他们在内核微架构上的路线图:

但在整个2018年中,Intel都没有发布其PAO战略应该有的下一步,代号为Ice Lake的第二代10nm处理器,直到2019年年中,Intel终于在台北电脑展的发布会上面公开了该系列的具体详情,它可以说是Intel在2015年推出Skylake以来幅度最大的处理器升级,引入了诸多新特性。而在8月份,Intel正式宣布该系列处理器上市,在去年年末和今年年初一段时间,我们看到了大量搭载Ice Lake的处理器。但是尴尬的事情又再次发生了,Ice Lake系列的性能被发现打不过自家另外一系列的移动处理器,也就是代号为Comet Lake-U的14nm处理器。
%20-%20EMBARGO%2010pm%20PT%20on%201.5-7pm-page-027.jpg)
%20-%20EMBARGO%2010pm%20PT%20on%201.5-7pm-page-026.jpg)
上面两张图来自于Intel官方的宣传资料,他们拿AMD Ryzen 7 3700U分别对比了自家的Core i7-1065G7(Ice Lake)和Core i7-10710U(Comet Lake),后者同为TDP为15W的产品,但比前者要多两个核心,同时还有更高的睿频。从图上可以看到,Core i7-1065G7在不少场景下是比不过Core i7-10710U的。现在更有坊间的爱好者对Ice Lake进行了更为详尽的测试,其能耗比真的只能用失望两个字来形容。
看起来Intel解决了新制程生产良率的问题,却没有解决能耗比的问题,现在的10nm被卡在高发热量、频率上不去、上不了桌面端等等问题之中,实属非常尴尬。就在Intel被新工艺延期折腾的时候,竞争对手已经推出了第三代Ryzen处理器,并用上了经过大幅改良的Zen 2架构。
Zen 2与Renoir:AMD实现逆转的最后一块拼图
AMD在Zen架构获得一定成功后继续改良,推出了一代小改的Zen+,然后同样在2019年的台北电脑展上面,他们发布了基于Zen 2架构的第三代Ryzen处理器。Zen 2针对Zen架构单核性能不足的问题进行了针对性的加强,更为重要的是,AMD从内核微架构到内核互联到封装形式再到制程工艺上,全部都进行了脱胎换骨般的革新,这里我们不多谈细节,而是看到最终的成品上面去。桌面版Ryzen 3000处理器因为有优秀的性能表现和较为平实的价格而获得了广大消费者的认可,而基于同样架构、面向服务器市场的第二代EPYC处理器已经被Amazon和微软Azure等数据中心启用,而后推出的面向高端桌面及工作站的第三代线程撕裂者更是大幅度打破了Intel在这块领域的性能优势,甚至Linux之父Linus在上个礼拜也放弃了一直使用的Intel平台,换了颗Threadripper 3970x,还被这颗处理器的表现所折服了。
这也是自K8以来,AMD十余年时间首次在桌面端拥有了与Intel不分伯仲的实力,在企业级市场中的份额也有一定的上升。一片向好的情况下,移动市场成了Intel最后的遮羞布。然而……
在今年年初的CES上,AMD发布了代号为Renoir的Ryzen 4000系列APU,它将Zen 2内核与其他模块融合到了一块Die上面,最高提供8核16线程的配置,需要注意的是,就算是低压的15W版本,也有8核16线程的高配,这是以往在移动平台上从来没出现过的,此前Intel也就是把核心数推高到了6个而已,关键是,它凭借着工艺优势,在同样的TDP空间内提供了更好的性能。
Renoir的意义并不只限于给低压平台提供新的8核而已,它是AMD认真为移动平台打造的一代APU。为什么说是认真呢?前两代Ryzen APU的表现实际上还可以,也收获了一定的市场认可,诸如华为等新兴笔记本品牌都推出了基于这两代APU的廉价笔记本,甚至微软为自家的Surface Laptop还定制了一颗APU。但问题在于,由于核心调度、待机功耗等等地方没有做的很好,使用这两代APU的笔记本在续航表现上较为一般,性能只能说是将将够用,所以大的OEM并不是太买账。
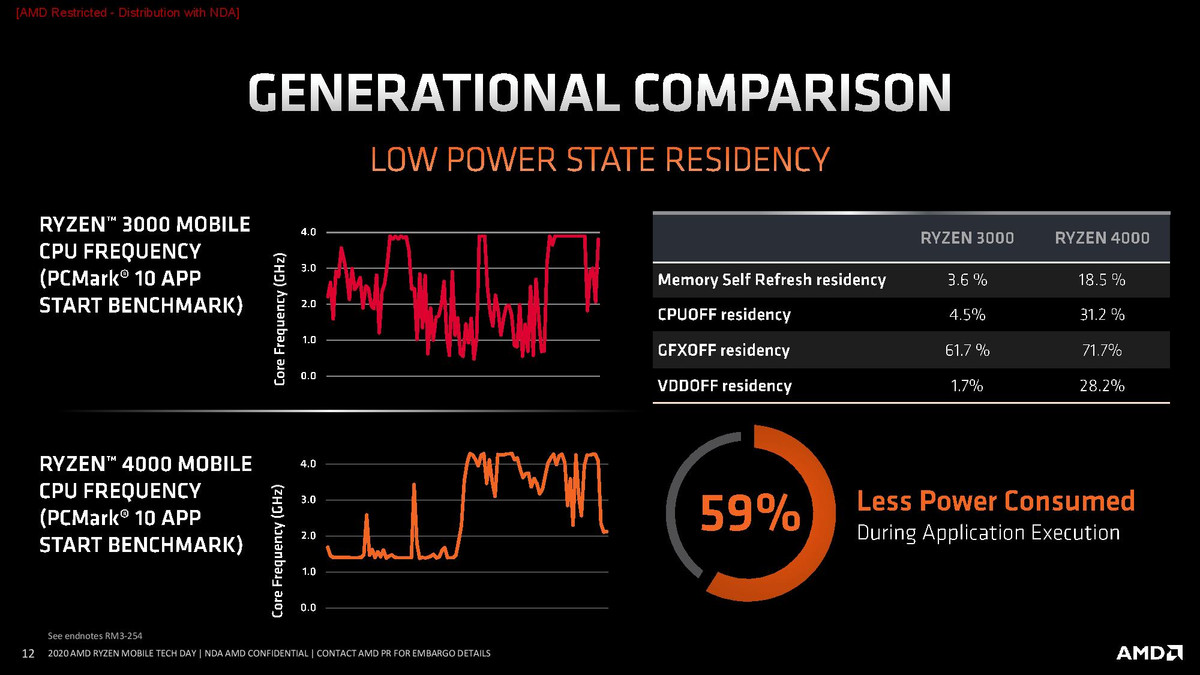
而Renoir则是针对这些小毛病进行了认真的改进,尤其是在节能方面,配合上台积电优秀的制程工艺,Renoir在续航方面实现了突飞猛进般的提升,直追、甚至超过了Ice Lake平台的表现。在看到Renoir的改进之后,今年大的OEM纷纷开始大量采用Renoir APU,推出的产品有像联想小新系列的主流级学生本,有天选、R7000这样引发大量话题关注的高性价比游戏本,甚至AMD还和华硕合作搞出了幻14这样炫技的产品,这些都是对该系列的认可。
Renoir成功地将Intel的最后一块遮羞布给揭下了,几乎在全平台实现了逆转。那么Intel现在有给出什么应对手段吗?
Tiger Lake与Rocket Lake:Intel能否摆脱困境?
Intel的优势很大程度上来自于自家的制程工艺,原本他们的工艺平均领先其他代工厂约3.5年,但在14nm和10nm的两次延期之后,这种优势已经荡然无存了,台积电的N7在相当程度上接近、甚至超过了Intel的10nm工艺,而他们在N7之后的下一代制程——N5,已经被用于量产苹果今年的A14处理器了。
Intel面对着严峻的考验,当然他们有着这么大的家底,肯定是不会坐以待毙的。同样在年初的CES 2020上,Intel在自己的主题演讲末尾终于是提到了自己在移动端布局的新平台——Tiger Lake。

Tiger Lake可以说是Ice Lake的优化版本,不过优化力度有点强,主要有换用新的Willow Cove内核,换上Intel研发已久的Xe GPU架构,并且使用10nm+的工艺进行制造,在频率上面有所提升。从目前泄漏的各种跑分成绩来看,Tiger Lake在一定程度上走回了性能增长的正轨,有望在移动端与Renoir进行对抗,不过,它最多应该只有四核版本。
Tiger Lake仅会在移动端露面,而对于竞争乏力的桌面端,Intel规划了名为Rocket Lake的平台,它仍将会使用14nm++制程,不过它终于摆脱了使用多年的Skylake内核,换上新的Sunny Cove/Willow Cove内核,在IPC上面有较大进步。配合上14nm++能够提供的较高频率,有望提供一次较大的性能提升。
但问题在于,竞争对手并不是静止的。AMD方面仍然在按他们既定的路线图走着,明年的CPU市场仍然是风云变换的一年,Intel能否摆脱当前的困境,很大程度在于明年这些新东西的表现。
总结:受制程拖累是大头,但战略跟不上变化也存问题
在文章的结尾,我们还是回归本文的标题,分析一下Intel是怎么失去自己的性能优势地位的。在前文谈及Intel两次受到制程拖累时,其实已经谈到了Intel在战略上反映过慢、处于被动的迹象,这也是除开制程之外的另一个拖累Intel处理器性能发展的问题。
我们经常戏称Intel、佳能等一些厂商为“牙膏厂”,原因在于,他们产品的代际性能提升相当有限,就像挤牙膏一般,明明有这么一大管,每次挤却总是那么一丢丢。作为半导体芯片行业的领头羊,Intel的技术储备方面是很丰厚的,他们也完全有能力在制程受限的情况下对架构进行更新实现更大幅度的性能增长,结果他们并没有选择这条成本较高的发展路线,而是通过一手“拖”字决,靠着加核心提频率的“秘诀”,让自己的产品不至于很难看,但端上来的Coffee Lake、Coffee Lake Refresh和Comet Lake这三代产品实在难以说是有诚意,一次又一次的挤牙膏消费的是自己品牌的形象,也让竞争对手得以缓缓接近自己,甚至大有弯道超车的趋势。
虽然Intel处理器的游戏表现依旧优异,但其实这部分的优势很大程度上来自于它的Ringbus总线和超高的频率,而不是内核架构。在将核心数和频率提升到极限之后,Intel终于才开始规划内核上的升级,但此时又被制程给限制住了,在下一代Rocket Lake处理器上我们很有可能会看到最大核心数量倒退的情况。
在这里说如果已经是马后炮,只能看向未来。从目前在各种渠道中得知的情况来看,Intel在未来的一两年中面对的挑战相当严峻,Tiger Lake早期工程样片的表现仍然不尽如人意、Rocket Lake的功耗被继续推高,更远的Alder Lake甚至将引入还没有正式表现的8+8大小核设计,用现在的眼光来看,这几个都不是什么好消息。不过传奇人物Jim Keller已经被Intel招至麾下,挑起技术部门的大梁,他将带给Intel什么样的变化现在还不得而知,但从他的传奇经历来看,总体是偏向好的。
很多人说,Intel的收入大头不在消费级,而是在企业级,其实这种说法并不准确。Intel的主要收入来自于CCG与DCG这两个部门,前者面向消费级市场,产品就是我们日常见到的这些消费级CPU;DCG部门面向数据中心市场,产品是服务器级别的CPU(和其他AI方面的产品)。在最近几个财年中,CCG与DCG的收入基本持平,CCG稍多几个百分点,但消费级产品的颓势已经明显影响到了部门的收入,上个财年CCG的收入增长几乎停滞,只有0.1%。而DCG的发展情况仍然大好。
总而言之,14nm和10nm的两次延期让Intel将自己工艺上平均领先3.5年的优势给消磨殆尽,而战略上的迟缓应对让他们逐渐处于被动地位。未来一到两年之内,他们相对弱势的情况不会有很大的改变,如果不对目前“挤牙膏”的现状做出改变,那“AMD,Yes”的口号,真的会越来越深入人心了。










 一个白色台球在绿色桌面上面运动
一个白色台球在绿色桌面上面运动
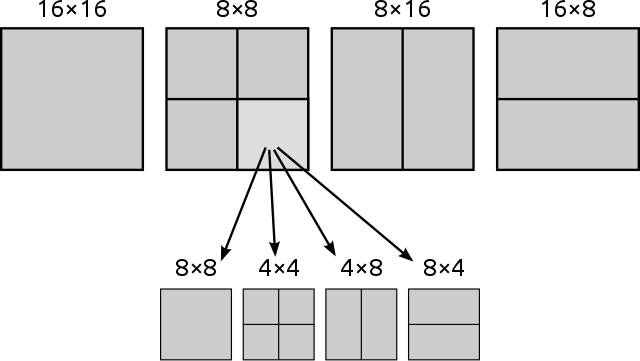
 将8x8个像素分成一个块
将8x8个像素分成一个块
 亮度通道做DCT变换后的图像,可以看到上方颜色连续部分非常平坦,而下方则拥有诸多细节
亮度通道做DCT变换后的图像,可以看到上方颜色连续部分非常平坦,而下方则拥有诸多细节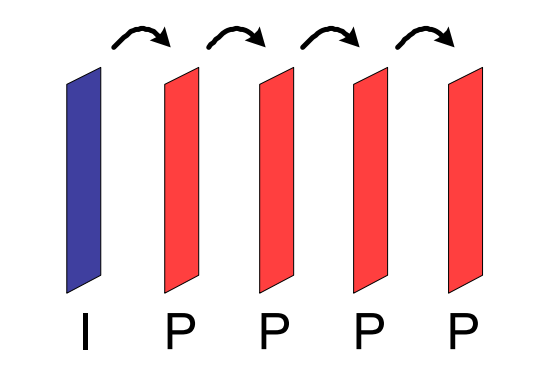
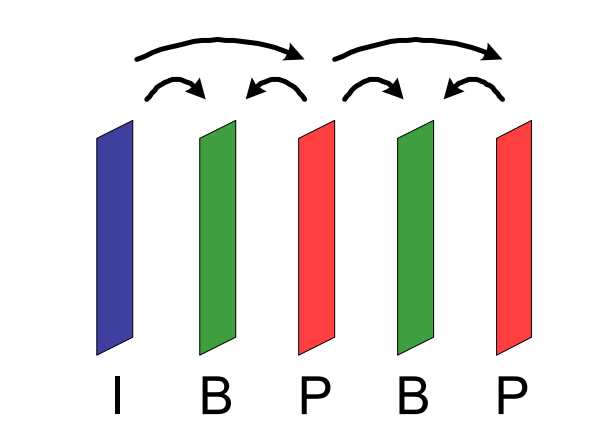
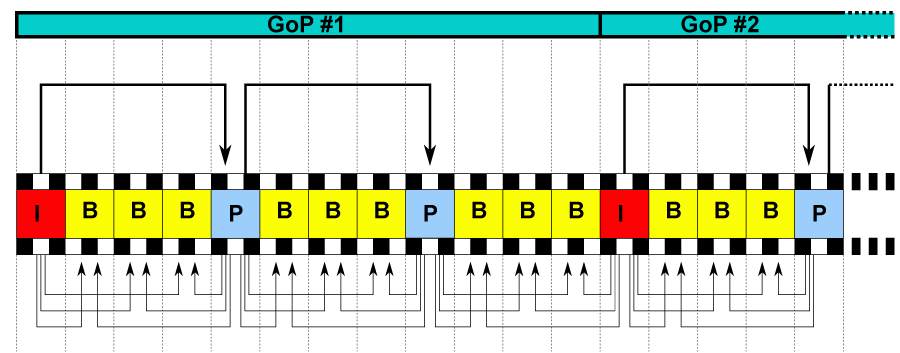

 每个宏块包含的预测模式信息
每个宏块包含的预测模式信息 差分图像加上预测信息可以还原出原始图像
差分图像加上预测信息可以还原出原始图像

 Digital Foundry推测中的Xbox Series X GPU规格
Digital Foundry推测中的Xbox Series X GPU规格
 左:VRS关;右:VRS开
左:VRS关;右:VRS开 上:VRS关;下:VRS开。现在区别就小了很多。
上:VRS关;下:VRS开。现在区别就小了很多。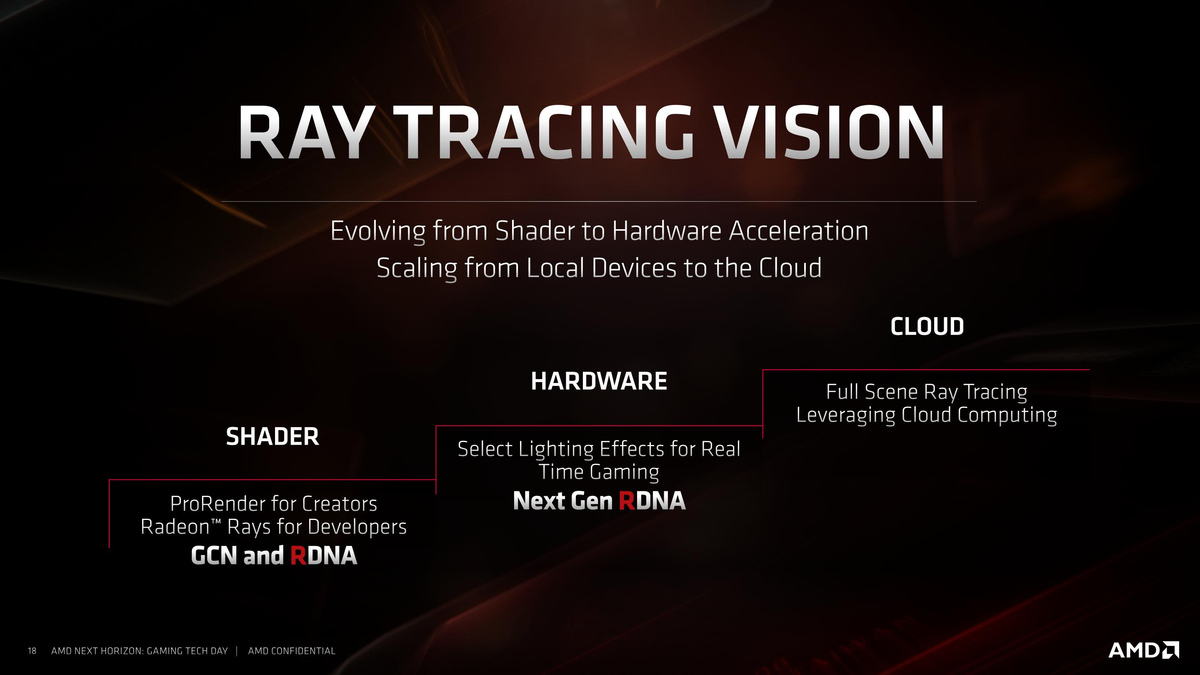



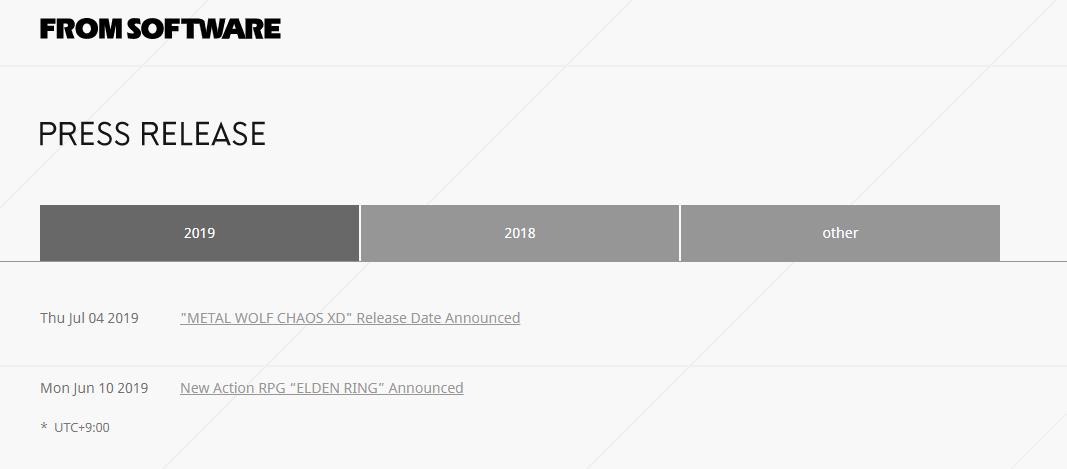 FromSoftware 的新闻稿页面
FromSoftware 的新闻稿页面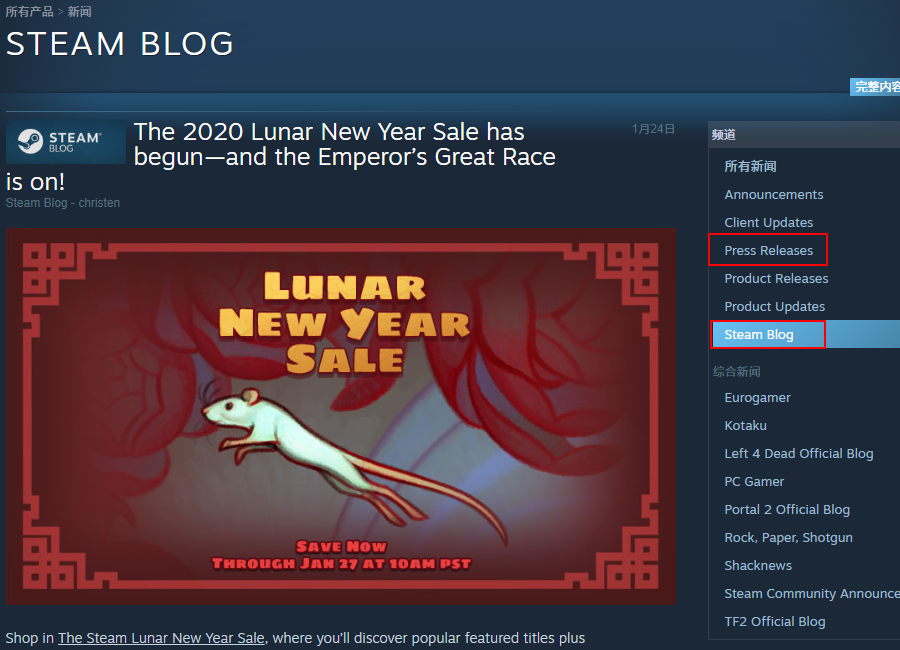 Steam 新闻页中的 Press Releases 已经很久没更新了
Steam 新闻页中的 Press Releases 已经很久没更新了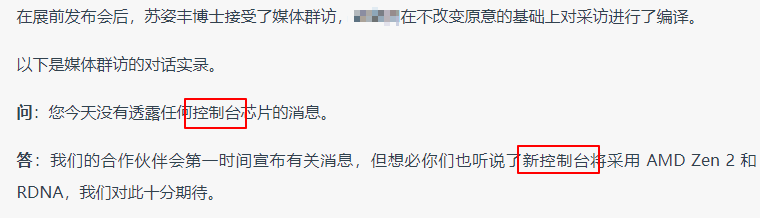 Console,一词多意,这里被错误翻译成了“控制台”
Console,一词多意,这里被错误翻译成了“控制台”
 到了某媒体那儿,流言提示就没了,变成肯定了
到了某媒体那儿,流言提示就没了,变成肯定了 不点名了,都是友媒
不点名了,都是友媒
 一些网站也会把 RSS 通道做到页面底部去,比如机核就是
一些网站也会把 RSS 通道做到页面底部去,比如机核就是